Medical Document Entity Extraction
Built an intelligent pipeline to extract entities from complex medical documents using multimodal LLMs (OpenAI, QWEN3). Handles messy layouts, handwritten notes, and multi-page correlations. Improved extraction accuracy from 84% to 88% while eliminating weekly fine-tuning cycles.
The problem
Medical and insurance documents often mix printed forms, handwritten notes, and messy layouts. Fields can span multiple pages, and legacy forms vary widely in structure.
Teams were spending hours on manual extraction and still missing critical fields. The previous system required weekly fine-tuning to keep up with new form types, and accuracy plateaued around 84%.
The solution
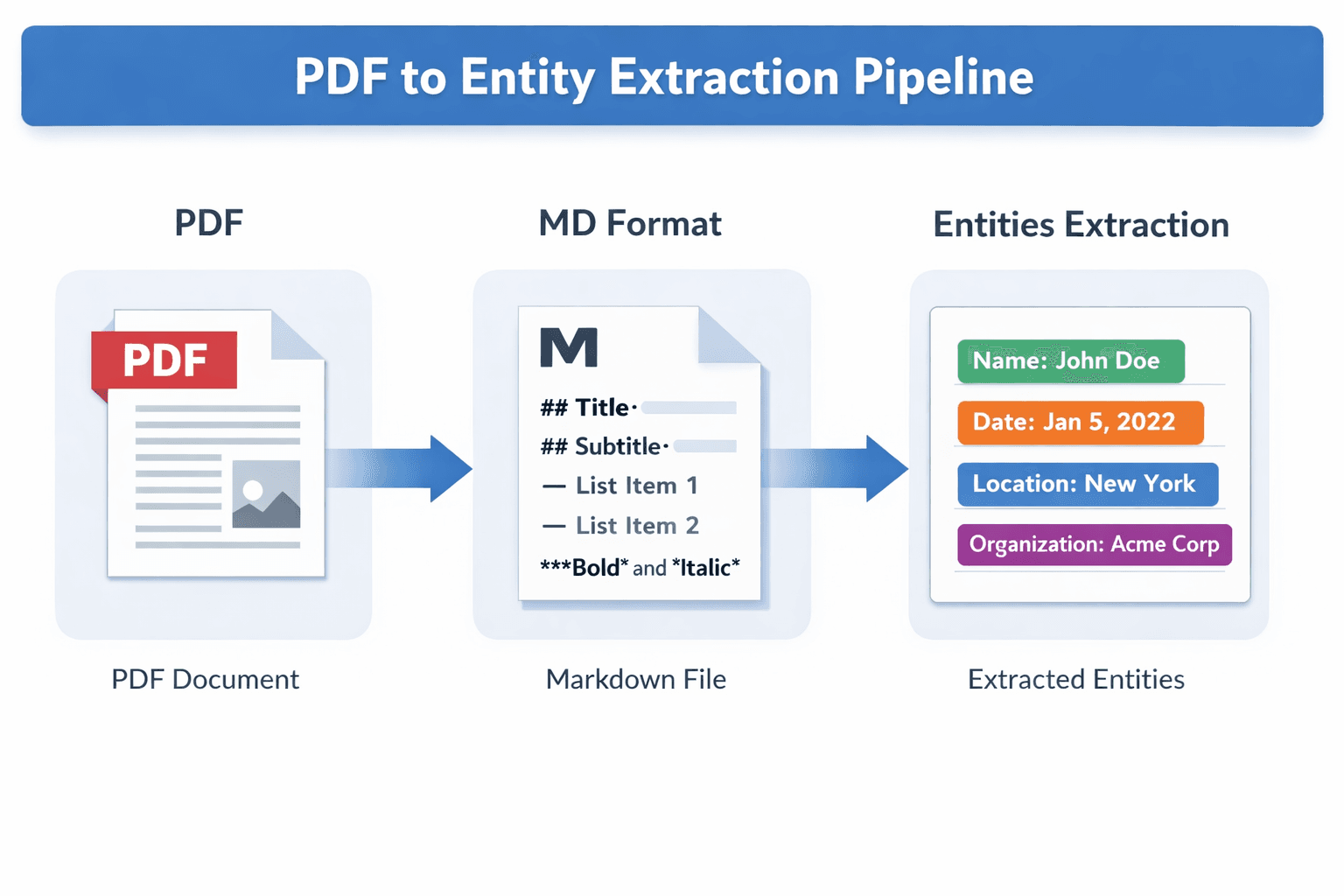
We built a multimodal extraction pipeline using LLMs (OpenAI, QWEN3) and LangGraph. The pipeline ingests raw document images and layout metadata, then runs structured extraction with fallbacks for low-confidence regions.
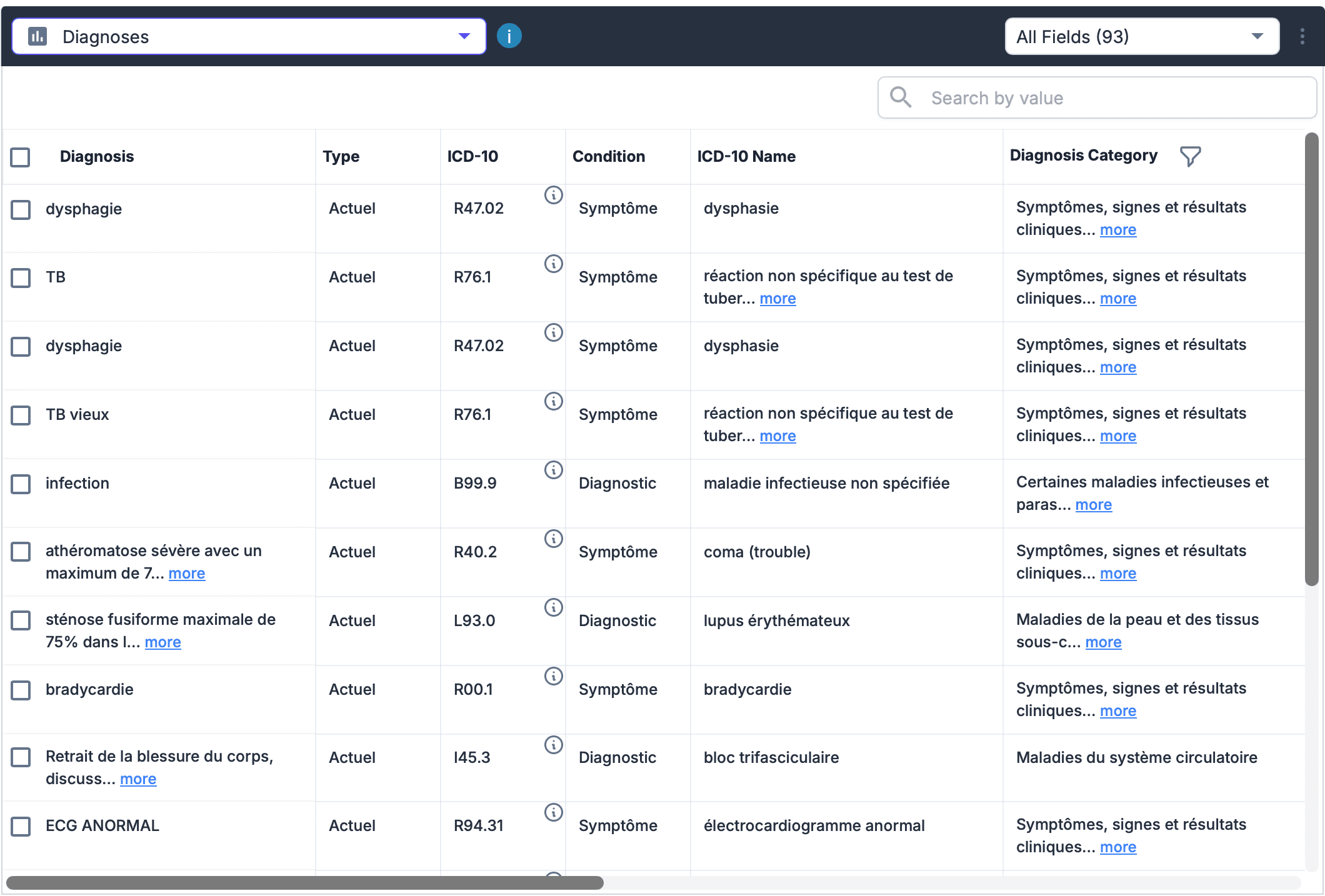
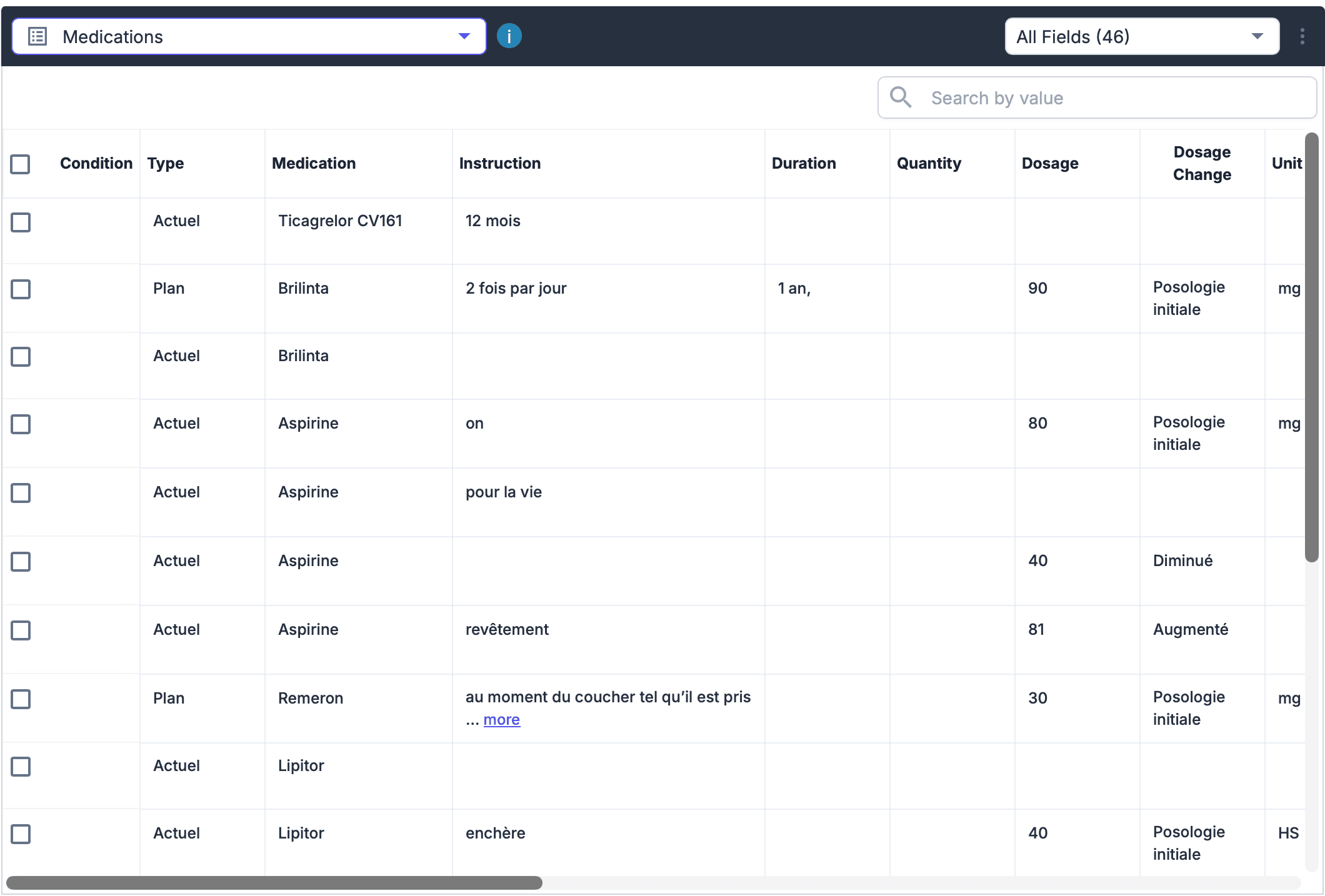
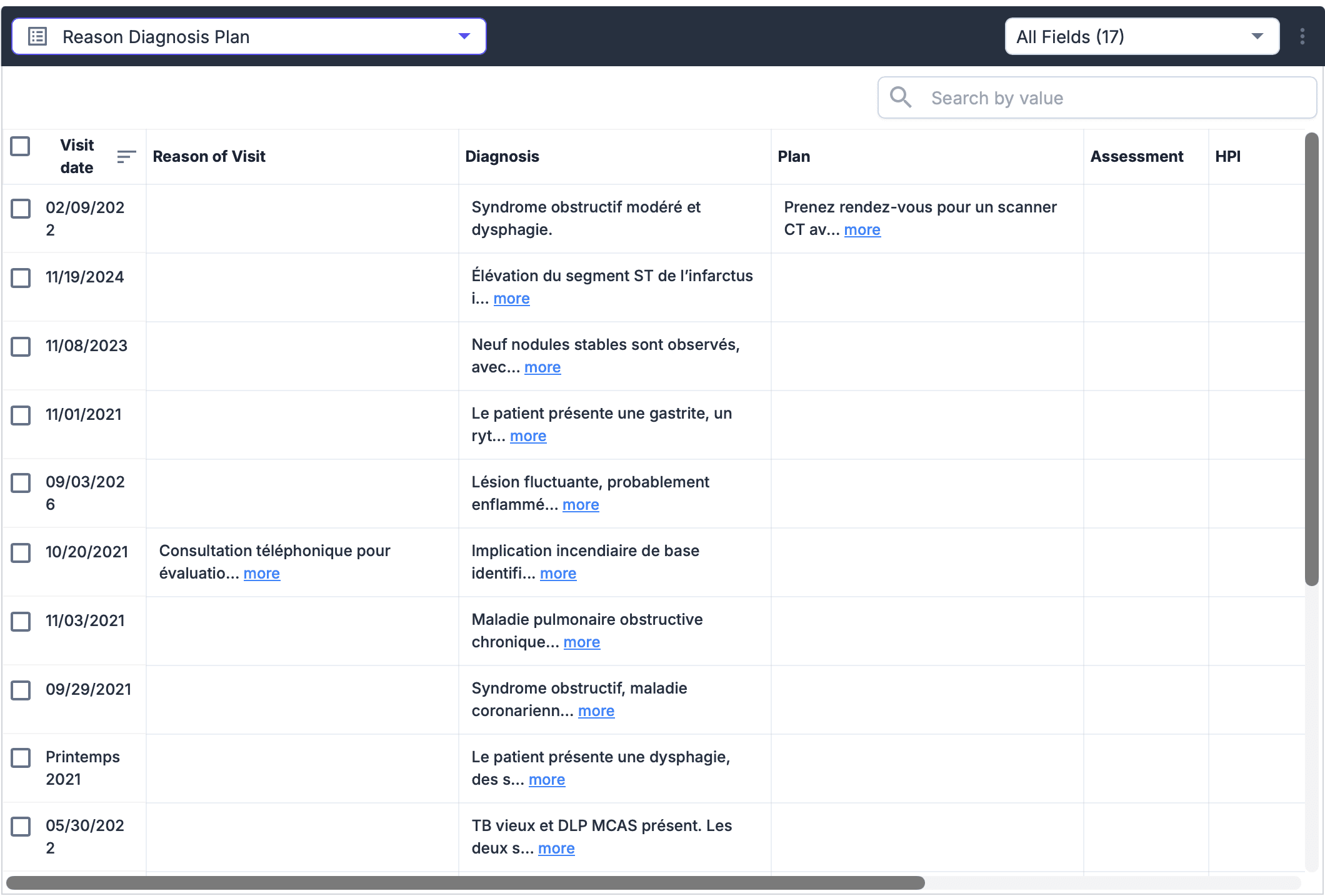
The system handles multi-page correlation so entities like patient name or policy number are resolved consistently across pages. Output is normalized and validated before downstream systems consume it.
Challenges
Handwritten text and overlapping printed content required careful prompt design and fallback models. We had to balance latency and cost across multiple LLM providers while keeping accuracy high.
Outcomes
Extraction accuracy improved from 84% to 88%.
Weekly fine-tuning cycles were removed; the system generalizes better with fewer updates. Manual review time dropped significantly.